Table Of Content

Neither matching nor blocking is necessary in studies with large sample sizes, since in these cases, simple randomization alone is enough to balance study groups. The term experimental design refers to a plan for assigning experimental units to treatment conditions. Finally, for large sample sizes, matching is not necessary since the study groups are already balanced at baseline just by randomn assignment.
Matched Pairs Design: Definition + Examples
Variables such as gender and age cannot be modified and therefore are perfect candidates to be used for matching. For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design. We expect the participants to learn better in “no noise” because of order effects, such as practice. However, a researcher can control for order effects using counterbalancing.
Regression vs. Classification: What’s the Difference?
Think of matched pairs design like a before-and-after makeover show. Each participant is paired with someone who has similar physical features, and then one person gets a makeover while the other remains unchanged. By comparing their outcomes, we can see if the makeover had any effect. Matched pairs design is a research method where each participant is paired with another participant who has similar characteristics, and then one member of the pair receives the treatment while the other serves as a control. This helps to eliminate confounding variables and increase the validity of the study.
Qualitative vs. Quantitative Variables: What’s the Difference?
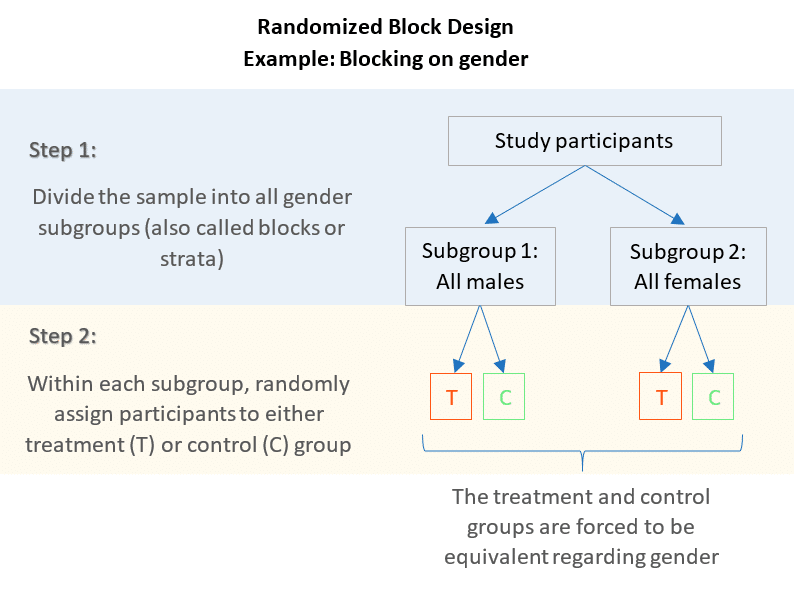
A matched pairs design is an experimental design where pairs of participants are matched in terms of key variables, such as age or socioeconomic status. One member of each pair is then placed into the experimental group and the other member into the control group. At the end of the time time period of 2 months, researchers will measure the total weight gain for each subject.
Experimental Design: Types, Examples & Methods
The variable the experimenter manipulates (i.e., changes) is assumed to have a direct effect on the dependent variable. To compare the effectiveness of two different types of therapy for depression, depressed patients were assigned to receive either cognitive therapy or behavior therapy for a 12-week period. Introduction to Statistics is our premier online video course that teaches you all of the topics covered in introductory statistics.
Find a fun patterned rug you absolutely love, and add in complementary patterns and hues from there, like subtle wallpaper or striped accent pillows. In this manner, any distinction in weight reduction that we notice can be credited to the eating routine, instead of old enough or orientation. I am Georges Choueiry, PharmD, MPH, and PhD student in epidemiology. I created this website to help researchers conduct studies from concept to publication. It also ensures the inclusion of a pre-specified number of participants from each category, therefore the results will be more generalizable.
I’m passionate about statistics, machine learning, and data visualization and I created Statology to be a resource for both students and teachers alike. My goal with this site is to help you learn statistics through using simple terms, plenty of real-world examples, and helpful illustrations. While we love a jute area rug or a grounding neutral, a traditional pattern is a great way to set the palette and tone for the space.
Geographic pair matching in large-scale cluster randomized trials - Nature.com
Geographic pair matching in large-scale cluster randomized trials.
Posted: Mon, 05 Feb 2024 08:00:00 GMT [source]
Advantages & Disadvantages of a Matched Pairs Design
If you take a hard look at any pattern-heavy, maximalist spaces, you’ll notice that each print feels wildly different, yet somehow cohesive as a whole. To compare two means we are obviously working with two groups, but first we need to think about the relationship between them. The groups are classified either as independent or dependent. Independent samples consist of two samples that have no relationship, that is, sample values selected from one population are not related in any way to sample values selected from the other population. Dependent samples consist of two groups that have some sort of identifiable relationship. For example, maybe researchers are interested in the effect aspirin has in preventing heart attacks.
All variables which are not independent variables but could affect the results (DV) of the experiment. Extraneous variables should be controlled where possible. In our previous example, each subject in the experiment was only placed on one diet. If instead we made one subject use the standard diet for 30 days, then the new diet for 30 days, there could be an order effect due to the fact that the subject used one particular diet before the other.
Because once we prove the influence of these risk factors on the outcome, we can takes steps to help people modify their lifestyle in a certain direction. In other words, if we take each pair alone, the choice of who gets the treatment and who doesn’t is completely randomized. Condition one attempted to recall a list of words that were organized into meaningful categories; condition two attempted to recall the same words, randomly grouped on the page. To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions.
In cases where matching takes a lot of time and work to implement, we can instead invest in increasing the sample size and running a simple randomized controlled experiment. For example, a lot of outcomes are gender and age specific. Therefore, matching individuals on these 2 variables will help improve the validity of the study by reducing bias. Confidence intervals may be calculated on their own for two samples but often, especially in the case of matched pairs, we first want to formally check to see if a difference exists with a hypothesis test. If we do find a statistically significant difference then we may estimate it with a CI after the fact.

Repeated Measures design is also known as within-groups or within-subjects design. This should be done by random allocation, ensuring that each participant has an equal chance of being assigned to one group. Statology Study is the ultimate online statistics study guide that helps you study and practice all of the core concepts taught in any elementary statistics course and makes your life so much easier as a student. I have a Masters of Science degree in Applied Statistics and I’ve worked on machine learning algorithms for professional businesses in both healthcare and retail.
A study was conducted to investigate the effectiveness of hypnotism in reducing pain. Results for randomly selected subjects are shown in the figure below. The “before” value is matched to an “after” value and the differences are calculated. Are the sensory measurements, on average, lower after hypnotism?
Inside JZ Microphones and the BT 202 Stereo Pair - Mixdown
Inside JZ Microphones and the BT 202 Stereo Pair.
Posted: Thu, 18 Apr 2024 07:00:00 GMT [source]
This will certainly be an issue since the causal association between risk factors, matching variables and outcome should be well understood in order to decide on which variable(s) to match. One of the major problems of matching is the difficulty to find appropriate matches. In some cases we may be forced to remove a number of participants from the study if appropriate matches could not be found. This may be a source of bias if participants with certain characteristics have a higher probability than others of being excluded. The principle of random allocation is to avoid bias in how the experiment is carried out and limit the effects of participant variables.
Order effect refers to differences in outcomes due to the order in which experimental materials are presented to subjects. By using a matched pairs design, you don’t have to worry about order effect since each subject only receives one treatment. Then, within each pair, one subject will randomly be assigned to follow the new diet for 30 days and the other subject will be assigned to follow the standard diet for 30 days. At the end of the 30 days, researchers will measure the total weight loss for each subject. To perform statistical inference techniques we first need to know about the sampling distribution of our parameter of interest. Remember although we start with two samples, the differences are the data we are interested in and our parameter of interest is μd, the mean difference.